He's right, in that Big Data doesn't
necessarily lead to big money, but I think he exaggerates for pedagogical effect. Why he feels the need to do so is instructive, especially for Big Data acolytes.
Some days ago there was agitation in the Big Data sociosphere when an interview by Wharton marketing professor Peter Fader questioned the value of Big Data. In
The Tech, Fader says
[The hype around Big Data] reminds me a lot of what was going on 15 years ago with CRM (customer relationship management). Back then, the idea was "Wow, we can start collecting all these different transactions and data, and then, boy, think of all the predictions we will be able to make." But ask anyone today what comes to mind when you say "CRM," and you'll hear "frustration," "disaster," "expensive," and "out of control." It turned out to be a great big IT wild-goose chase. And I'm afraid we're heading down the same road with Big Data. [Emphasis added.]
I think Pete's big point is correct, that Big Data
by itself (to be understood as: including the computer science and the data analysis tools, not just the data -- hence the capitalization of "Big Data") is not sufficient for Big Money. I think that he's underestimating, for pedagogical effect, the role that Big Data
with the application of appropriate business knowledge can have in changing the way we do marketing and the sources of value for customers (that is both the job of marketer and the foundations of business).
This is something I've
blogged about before.
So, why make a point that seems fairly obvious (domain knowledge is important, not just data processing skills), and especially why make it so pointedly in a field that is full of strong personalities?
First, since a lot of people working in Big Data don't know technical marketing, they keep reinventing and rediscovering old techniques. Not only is this a duplication of work, it also ignores all knowledge of these techniques' limitations, which has been developed by marketers.
As an example of marketing knowledge that keeps being reinvented, Pete talks about the discovery of Recency-Frequency-Money in direct marketing,
The "R" part is the most interesting, because it wasn't obvious that recency, or the time of the last transaction, should even belong in the triumvirate of key measures, much less be first on the list.* [...]
Some of those old models are really phenomenal, even today. Ask anyone in direct marketing about RFM, and they'll say, "Tell me something I don't know." But ask anyone in e-commerce, and they probably won't know what you're talking about. Or they will use a lot of Big Data and end up rediscovering the RFM wheel—and that wheel might not run quite as smoothly as the original one.
Second, some of the more famous applications of machine learning, for example the Netflix prize and computers beating humans at chess, in fact corroborate the importance of field-specific knowledge. (In other words, that which many Big Data advocates seem to believe is not important, at least as far as marketing is concerned.)
Deep Blue, the specialized chess-playing computer that defeated Kasparov, had large chess-specific pattern-matching and evaluation modules; and as for the Netflix prize, I think
Isomorphismes's comment says all:
The winning BellKor/Pragmatic Chaos teams implemented ensemble methods with something like 112 techniques smushed together. You know how many of those the Netflix team implemented? Exactly two: RBM’s and SVD. [...]
Domain knowledge trumps statistical sophistication. This has always been the case in the recommendation engines I’ve done for clients. We spend most of our time trying to understand the space of your customers’ preferences — the cells, the topology, the metric, common-sense bounds, and so on.
Third, many people who don't know any technical marketing tools continuously disparage marketing (and its professionals), and some do so from positions of authority and leadership. That disparagement, repeated and amplified by me-too retweets and Quora upvotes, is what makes reasonable people feel the need for pointedly making their points.
Here are two paraphrased tweets by people in the Big Data sociosphere; I paraphrased them so that the authors cannot be identified with a simple search, because my objective is not to attack them but rather illustrate a more widespread attitude:
It's time marketing stopped being based on ZIP codes. (Tweeted by a principal in an analytics firm.)
Someone should write a paper on how what matters to marketing is behavior not demographics. (Tweeted by someone who writes good posts on other topics.)
To anyone who knows basic marketing, these tweets are like a kid telling a professional pianist that "we need to start playing piano with all fingers, not just the index fingers" and "it's possible to play things other than 'chopsticks' on the piano." (Both demographics and ZIP codes have been superseded by better targeting approaches many decades ago.)
These tweets reflect a sadly common attitude of Big Data people trained in computer science or statistics: that the field of marketing cannot possibly be serious, since it's not computer science or statistics. This attitude in turn extends to each of these fields: many computer scientists dismiss statistics as something irrelevant given enough data and many statisticians dismiss computer scientists as just programmers.
That's a pernicious attitude: that what has been known by others isn't worth of consideration, because we have a shiny new tool. That attitude needs deflating and that's what Pete's piece does.
-- -- -- --
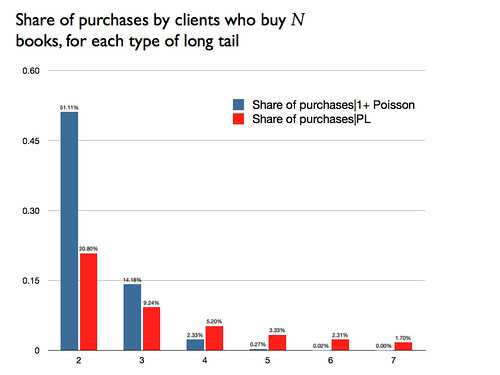
* An explanation of the importance of recency is that it's a proxy for "this client is still in a relationship with our firm." There's a paper by Schmittlein, Morrison, and Colombo, "Counting your customers,"
Management Science,
v33
n1 (1987), that develops a model of market activity using a two-state model: the purchases are Poisson with unknown $\lambda$ in one of the states (active) and there's an unobserved probability of switching to the other state (inactive), which is absorbing and has no purchases. Under some reasonable assumptions, they show that recency increases the probability that the consumer is in the active state. BTW, I'm pretty sure that it was Pete Fader who told me about this paper, about ten years or so ago.




{kind=link}
{kind=link}
{kind=link}