There's a lot of talk about long tails, both in finance (where fat tails, a/k/a kurtosis, turn hedging strategies into a false sense of safety) and in retail (where some people think they just invented niche marketing). I leave finance for people with better salaries brainpower, and focus only on retail for my examples.
A lot of money can be made serving the customers on the long tail; that much we already knew from decades of niche marketing. The question is how much, and for this there are quite a few considerations; I will focus on the difference between exponential decay (Poisson) long tails and hyperbolic decay (power law) long tails and how that difference would impact different emphasis on long tail targeting (that is, how much to invest going after these niche customers), say for a bookstore.
A lot of money can be made serving the customers on the long tail; that much we already knew from decades of niche marketing. The question is how much, and for this there are quite a few considerations; I will focus on the difference between exponential decay (Poisson) long tails and hyperbolic decay (power law) long tails and how that difference would impact different emphasis on long tail targeting (that is, how much to invest going after these niche customers), say for a bookstore.
A Poisson distribution over $N\ge 0$ with parameter $\lambda$ has pdf:
$ \Pr(N=n|\lambda) =\frac{\lambda^{n}\, e^{-\lambda}}{n!}$.
A discrete power law (Zipf) distribution for $N\ge 1$ with parameter $s$ is given by:
$ \Pr(N=n|s) =\frac{n^{-s}}{\zeta(s)},$
where $\zeta(s)$ is the Riemann zeta function; note that it's only a scaling factor given $s$.
A couple of observations:
1. Because the power law has $\Pr(N=0|s)=0$, I'll actually use a Poisson + 1 process for the exponential long tail. This essentially means that the analysis would be restricted to people who buy at least one book. This assumption is not as bad as it might seem: (a) for brick-and-mortar retailers, this data is only collected when there's an actual purchase; (b) the process of buying a book at all -- which includes going to the store -- may be different from the process of deciding whether to buy a given book or the number of books to buy.
2. Since I'm not calibrating the parameters of these distributions on client data (which is confidential), I'm going to set these parameters to equalize the means of the two long tails. There are other approaches, for example setting them to minimize a measure of distance, say the Kullback-Leibler divergence or the mean square error, but the equal means is simpler.
The following diagram compares a Zipf distribution with $s=3$ (which makes $\mu=1.37$) and a 1 + Poisson process with $\lambda=0.37$ (click for larger):

The important data is the grey line, which maps into the right-side logarithmic scale: for all the visually impressive differences in the small numbers $N$ on the left, the really large ratios happen in the long tail. This is one of the issues a lot of probabilists point out to practitioners: it's really important to understand the behavior at the small probability areas of the distribution support, especially if they represent -- say -- the possibility of catastrophic losses in finance or the potential for the customers who buy large numbers of books.
An aside, from Seth Godin, about the importance of the heavy user segment in bookstores:
To illustrate the importance of even the relatively small ratios for a few books, this diagram shows the percentage of purchases categorized by size of purchase:
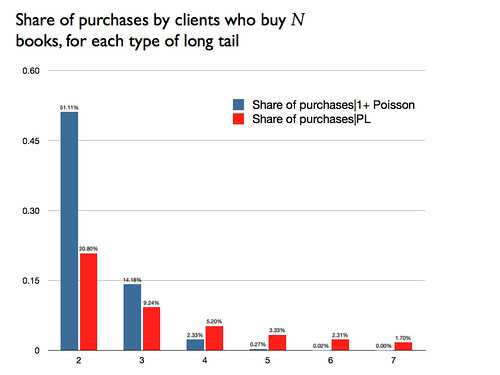
Yes, the large number of customers who buy a small number of books still gets a large percent of the total, but each of these is not a good customer to have: elaborating on Seth's post, these one-book customers are costly to serve, typically will buy a heavily-discounted best-seller and are unlikely to buy the high-margin specialized books, and tend to be followers, not influencers of what other customers will spend money on (so there are no spillovers from their purchase).
The small probabilities have been ignored long enough; finance is now becoming weary of kurtosis, marketing should go back to its roots and merge niche marketing with big data, instead of trying to reinvent the well-know wheel.
Lunchtime addendum: The differences between the exponential and the power law long tail are reproduced, to a smaller extent, across different power law regimes:

Note that the logarithmic scale implies that the increasing vertical distances with $N$ are in fact increasing probability ratios.
- - - - - - - - -
Well, that plan to make this blog more popular really panned out, didn't it? :-)
A couple of observations:
1. Because the power law has $\Pr(N=0|s)=0$, I'll actually use a Poisson + 1 process for the exponential long tail. This essentially means that the analysis would be restricted to people who buy at least one book. This assumption is not as bad as it might seem: (a) for brick-and-mortar retailers, this data is only collected when there's an actual purchase; (b) the process of buying a book at all -- which includes going to the store -- may be different from the process of deciding whether to buy a given book or the number of books to buy.
2. Since I'm not calibrating the parameters of these distributions on client data (which is confidential), I'm going to set these parameters to equalize the means of the two long tails. There are other approaches, for example setting them to minimize a measure of distance, say the Kullback-Leibler divergence or the mean square error, but the equal means is simpler.
The following diagram compares a Zipf distribution with $s=3$ (which makes $\mu=1.37$) and a 1 + Poisson process with $\lambda=0.37$ (click for larger):
The important data is the grey line, which maps into the right-side logarithmic scale: for all the visually impressive differences in the small numbers $N$ on the left, the really large ratios happen in the long tail. This is one of the issues a lot of probabilists point out to practitioners: it's really important to understand the behavior at the small probability areas of the distribution support, especially if they represent -- say -- the possibility of catastrophic losses in finance or the potential for the customers who buy large numbers of books.
An aside, from Seth Godin, about the importance of the heavy user segment in bookstores:
Amazon and the Kindle have killed the bookstore. Why? Because people who buy 100 or 300 books a year are gone forever. The typical American buys just one book a year for pleasure. Those people are meaningless to a bookstore. It's the heavy users that matter, and now officially, as 2009 ends, they have abandoned the bookstore. It's over.
To illustrate the importance of even the relatively small ratios for a few books, this diagram shows the percentage of purchases categorized by size of purchase:
Yes, the large number of customers who buy a small number of books still gets a large percent of the total, but each of these is not a good customer to have: elaborating on Seth's post, these one-book customers are costly to serve, typically will buy a heavily-discounted best-seller and are unlikely to buy the high-margin specialized books, and tend to be followers, not influencers of what other customers will spend money on (so there are no spillovers from their purchase).
The small probabilities have been ignored long enough; finance is now becoming weary of kurtosis, marketing should go back to its roots and merge niche marketing with big data, instead of trying to reinvent the well-know wheel.
Lunchtime addendum: The differences between the exponential and the power law long tail are reproduced, to a smaller extent, across different power law regimes:
Note that the logarithmic scale implies that the increasing vertical distances with $N$ are in fact increasing probability ratios.
- - - - - - - - -
Well, that plan to make this blog more popular really panned out, didn't it? :-)