I'm a little skeptical about online education. About 2/3 skeptical.
Most of the (traditional) teaching I received was squarely based on what I call the Dentist Model of Education: a [student|patient] goes into the [classroom|dentist's office] and the [instructor|dentist] does something technical to the [student|patient]. Once the professional is done, the [student|patient] goes away and [forgets the lecture|never flosses].
I learned almost nothing from that teaching. Like every other person in a technical field, I learned from studying and solving practice problems. (Rule of thumb: learning is 1% lecture, 9% study, 90% practice problems.)
A better education model, the Personal Trainer Model of Education asserts that, like in fitness training, results come from the [trainee|student] practicing the [movements|materials] himself/herself. The job of the [personal trainer|instructor] is to guide that practice and select [exercises|materials] that are appropriate to the [training|instruction] objectives.
Which is why I'm two-thirds skeptical of the goodness of online education.
Obviously there are advantages to online materials: there's low distribution cost, which allows many people to access high quality materials; there's a culture of sharing educational materials, spearheaded by some of the world's premier education institutions; there are many forums, question and answer sites and – for those willing to pay a small fee – actual online courses with instructors and tests.
Leaving aside the broad accessibility of materials, there's no getting around the 1-9-90 rule for learning. Watching Walter Lewin teaching physics may be entertaining, but without practicing, by solving problem sets, no one watching will become a physicist.
Consider the plethora of online personal training advice and assume that the aspiring trainee manages to find a trainer who knows what he/she is doing. Would this aspiring trainee get better at her fitness exercises by reading a web site and watching videos of the personal trainer exercising? And yet some people believe that they can learn computer programming by watching online lectures. (Or offline lectures, for that matter.*)
If practice is the key to success, why do so many people recognize the absurdity of the video-watching, gym-avoiding fitness trainee while at the same time assume that online lectures are the solution to technical education woes?
(Well-designed online instruction programs are much more than lectures, of course; but what most people mean by online education is not what I consider well-designed and typically is an implementation of the dentist model of education.)
The second reason why I'm skeptic (hence the two-thirds share of skepticism) is that the education system has a second component, beyond instruction: it certifies skills and knowledge. (We could debate how well it does this, but certification is one of the main functions of education institutions.)
Certification of a specific skill can be done piecemeal but complex technical fields depend on more than a student knowing the individual skills of the field; they require the ability to integrate across different sub-disciplines, to think like a member of the profession, to actually do things. That's why engineering students have engineering projects, medical students actually treat patients, etc. These are part of the certification process, which is very hard to do online or with short in-campus events, even if we remove questions of cheating from the mix.
There's enormous potential in online education, but it can only be realized by accepting that education is not like a visit to the dentist but rather like a training session at the gym. And that real, certified learning requires a lot of interaction between the education provider and the student: not something like the one-way lectures one finds online.
(This is not to say that there aren't some good online education programs, but they tend to be uncommon.)
Just like the best-equipped gym in the world will do nothing for a lazy trainee, the best online education platform in the world will do nothing for an unmotivated student. But a motivated kid with nothing but a barbell & plates can become a competitive powerlifter and a motivated kid a with a textbook will learn more than the hordes who watch online lectures while tweeting and facebooking.
The key success factor is not technology; it's the student. It always is.
ADDENDUM (Nov 27, 2011): I've received some comments to the effect that I'm just defending universities from the disruptive innovation of entrants. Perhaps, but:
Universities have several advantages over new institutions, especially when so many of these new institutions have no understanding of what technical education requires. If there was a new online way to sell hamburgers would it surprise anyone that McDs and BK were better at doing it than people who are great at online selling engineering but who never made an hamburger in their lives?
This is not to say that there isn't [vast] room to improve in both the online and offline offerings of universities. But it takes a massive dose of arrogance to assume that everything that went before (in regards to education) can be ignored because of a low cost of content distribution.
--------
* For those who never learned computer programming: you learn by writing programs and testing them. Many many many programs and many many many tests. A quick study of the basics of the language in question is necessary, but better done individually than in a lecture room. Sometimes the learning process can be jump-started by adapting other people's programs. A surefire way to not learn how to program is to listen to someone else talk about programming.
Friday, November 25, 2011
Thursday, November 24, 2011
Data cleaning or cherry-picking?
Sometimes there's a fine line between data cleaning and cherry-picking your data.
My new favorite example of this is based on something Nassim Nicholas Taleb said at a talk at Penn (starting at 32 minutes in): that 92% of all kurtosis for silver in the last 40 years of trading could be traced to a single day; 83% of stock market kurtosis could also be traced to one day in 40 years.
One day in forty years is about 1/14,600 of all data. Such a disproportionate effect might lead some "outlier hunters" to discard that one data point. After all, there are many data butchers (not scientists if they do this) who create arbitrary rules for outlier detection (say, more than four standard deviations away from the mean) and use them without thinking.
In the NNT case, however, that would be counterproductive: the whole point of measuring kurtosis (or, in his argument, the problem that kurtosis is not measurable in any practical way) is to hedge against risk correctly. Underestimating kurtosis will create ineffective hedges, so disposing of the "outlier" will undermine the whole point of the estimation.
In a recent research project I removed one data point from the analysis, deeming it an outlier. But I didn't do it because it was four standard deviations from the mean alone. I found it because it did show an aggregate behavior that was five standard deviations higher than the mean. Then I examined the disaggregate data and confirmed that this was anomalous behavior: the experimental subject had clicked several times on links and immediately clicked back, not even looking at the linked page. This temporally disaggregate behavior, not the aggregate measure of total clicks, was the reason why I deemed the datum an outlier, and excluded it from analysis.
Data cleaning is an important step in data analysis. We should take care to ensure that it's done correctly.
My new favorite example of this is based on something Nassim Nicholas Taleb said at a talk at Penn (starting at 32 minutes in): that 92% of all kurtosis for silver in the last 40 years of trading could be traced to a single day; 83% of stock market kurtosis could also be traced to one day in 40 years.
One day in forty years is about 1/14,600 of all data. Such a disproportionate effect might lead some "outlier hunters" to discard that one data point. After all, there are many data butchers (not scientists if they do this) who create arbitrary rules for outlier detection (say, more than four standard deviations away from the mean) and use them without thinking.
In the NNT case, however, that would be counterproductive: the whole point of measuring kurtosis (or, in his argument, the problem that kurtosis is not measurable in any practical way) is to hedge against risk correctly. Underestimating kurtosis will create ineffective hedges, so disposing of the "outlier" will undermine the whole point of the estimation.
In a recent research project I removed one data point from the analysis, deeming it an outlier. But I didn't do it because it was four standard deviations from the mean alone. I found it because it did show an aggregate behavior that was five standard deviations higher than the mean. Then I examined the disaggregate data and confirmed that this was anomalous behavior: the experimental subject had clicked several times on links and immediately clicked back, not even looking at the linked page. This temporally disaggregate behavior, not the aggregate measure of total clicks, was the reason why I deemed the datum an outlier, and excluded it from analysis.
Data cleaning is an important step in data analysis. We should take care to ensure that it's done correctly.
Sunday, November 13, 2011
Vanity Fair bungles probability example
There's an interesting article about Danny Kahneman in Vanity Fair, written by Michael Lewis. Kahneman's book Thinking: Fast And Slow is an interesting review of the state of decision psychology and well worth reading, as it the Vanity Fair article.
But the quiz attached to that article is an example of how not to popularize technical content.
This example, question 2, is wrong:
$p(math|eng) = 0.5$; half the engineers have math as a hobby.
$p(math|law) = 0.001$; one in a thousand lawyers has math as a hobby.
Then the posterior probabilities (once the description is known) are given by
I understand the representativeness heuristic, which mistakes $p(math|eng)/p(math|law)$ for $p(eng|math)/p(law|math)$, ignoring the base rates, but there's no reason to give up the inference process if some data in the description is actually informative.
-- -- -- --
* This example shows the elucidative power of working through some numbers. One might be tempted to say "ok, there's some updating, but it will probably still fall under the 10-40pct category" or "you may get large numbers with a disproportionate example like one-half of the engineers and one-in-a-thousand lawyers, but that's just an extreme case." Once we get some numbers down, these two arguments fail miserably.
Numbers are like examples, personas, and prototypes: they force assumptions and definitions out in the open.
But the quiz attached to that article is an example of how not to popularize technical content.
This example, question 2, is wrong:
A team of psychologists performed personality tests on 100 professionals, of which 30 were engineers and 70 were lawyers. Brief descriptions were written for each subject. The following is a sample of one of the resulting descriptions:
Jack is a 45-year-old man. He is married and has four children. He is generally conservative, careful, and ambitious. He shows no interest in political and social issues and spends most of his free time on his many hobbies, which include home carpentry, sailing, and mathematics.
What is the probability that Jack is one of the 30 engineers?No. Most people have knowledge beyond what is in the description; so, starting from the appropriate prior probabilities, $p(law) = 0.7$ and $p(eng) = 0.3$, they update them with the fact that engineers like math more than lawyers, $p(math|eng) >> p(math|law)$. For illustration consider
A. 10–40 percent
B. 40–60 percent
C. 60–80 percent
D. 80–100 percent
If you answered anything but A (the correct response being precisely 30 percent), you have fallen victim to the representativeness heuristic again, despite having just read about it.
$p(math|eng) = 0.5$; half the engineers have math as a hobby.
$p(math|law) = 0.001$; one in a thousand lawyers has math as a hobby.
Then the posterior probabilities (once the description is known) are given by
$p(eng|math) = \frac{ p(math|eng) \times p(eng)}{p(math)}$
$p(law|math) = \frac{ p(math|law) \times p(law)}{p(math)}$with $p(math) = p(math|eng) \times p(eng) + p(math|law) \times p(law)$. In other words, with the conditional probabilities above,
$p(eng|math) = 0.995$
$p(law|math) = 0.005$
Note that even if engineers as a rule don't like math, only a small minority does, the probability is still much higher than 0.30 as long as the minority of engineers is larger than the minority of lawyers*:
Yes, that last case is a two-to-one ratio of engineers who like math to lawyers who like math; and it still falls out of the 10-40pct category.$p(math|eng) = 0.25$ implies $p(eng|math) = 0.991$
$p(math|eng) = 0.10$ implies $p(eng|math) = 0.977$
$p(math|eng) = 0.05$ implies $p(eng|math) = 0.955$
$p(math|eng) = 0.01$ implies $p(eng|math) = 0.811$
$p(math|eng) = 0.005$ implies $p(eng|math) = 0.682$
$p(math|eng) = 0.002$ implies $p(eng|math) = 0.462$
I understand the representativeness heuristic, which mistakes $p(math|eng)/p(math|law)$ for $p(eng|math)/p(law|math)$, ignoring the base rates, but there's no reason to give up the inference process if some data in the description is actually informative.
-- -- -- --
* This example shows the elucidative power of working through some numbers. One might be tempted to say "ok, there's some updating, but it will probably still fall under the 10-40pct category" or "you may get large numbers with a disproportionate example like one-half of the engineers and one-in-a-thousand lawyers, but that's just an extreme case." Once we get some numbers down, these two arguments fail miserably.
Numbers are like examples, personas, and prototypes: they force assumptions and definitions out in the open.
Tuesday, November 1, 2011
Less
I found a magic word and it's "less."
On September 27, 2011, I decided to run a lifestyle experiment. Nothing radical, just a month of no non-essential purchases, the month of October 2011. These are the lessons from that experiment.
Separate need, want, and like
One of the clearest distinctions a "no non-essential purchases" experiment required me to make was the split between essential and non-essential.
Things like food, rent, utilities, gym membership, Audible, and Netflix I categorized as essential, or needs. The first three for obvious reasons, the last three because the hassle of suspending them wasn't worth the savings.
A second category of purchases under consideration was wants, things that I felt that I needed but could postpone the purchase until the end of the month. This included things like Steve Jobs's biography, for example. I just collected these in the Amazon wish list.
A third category was likes. Likes were things that I wanted to have but knew that I could easily live without them. (Jobs's biography doesn't fall into this category, as anyone who wants to discuss the new economy seriously has to read it. It's a requirement of my work, as far as I am concerned.) I placed these in the Amazon wish list as well.
Over time, some things that I perceived as needs were revealed as simply wants or even likes. And many wants ended up as likes. This means that just by delaying the decision to purchase for some time I made better decisions.
This doesn't mean that I won't buy something because I like it (I do have a large collection of music, art, photography, history, science, and science fiction books, all of which are not strictly necessary). What it means is that the decision to buy something is moderated by the preliminary categorization into these three levels of priority.
A corollary of this distinction is that it allows me to focus on what is really important in the activities that I engage in. I summarized some results in the following table (click for bigger):
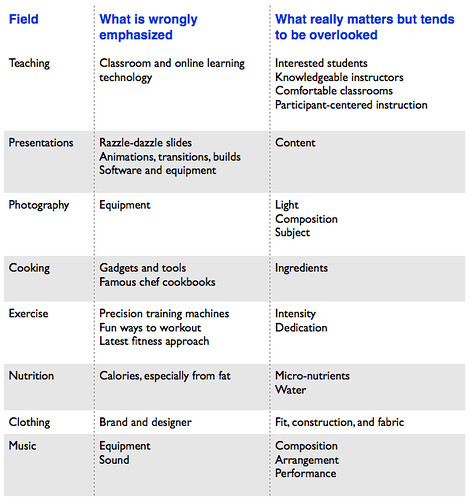
One of the regularities of this table is that the entries in the middle column (things that are wrongly emphasized) tend to be things that are bought, while entries in the last column (what really matters) tend to be things that are learned or experienced.
Correct accounting focusses on time, not on nominal money
Ok, so I can figure out a way to spend less in things that are not that necessary. Why is this a source of happiness?
Because money to spend costs time and I don't even get all the money.
When I spend one hour working a challenging technical marketing problem for my own enjoyment, I get the full benefit of that one hour of work, in the happiness solving a puzzle always brings me. When I work for one hour on something that I'd rather not be doing for a payment of X dollars, I get to keep about half of those X dollars (when everything is accounted for). I wrote an illustration of this some time ago.
In essence, money to spend comes, at least partially from doing things you'd rather not do, or doing them at times when you'd rather be doing something else, or doing them at locations that you'd rather not travel to. I like the teaching and research parts of my job, but there are many other parts that I do because it's the job. I'm lucky in that I like my job; but even so I don't like all the activities it involves.
The less money I need, the fewer additional things I have to do for money. And, interestingly, the higher my price for doing those things. (If my marginal utility of money is lower, you need to pay more for me to incur the disutility of teaching that 6-9AM on-location exec-ed seminar than you'd have to pay to a alternate version of me that really wants money to buy the latest glued "designer" suit.)
Clarity of purpose, not simply frugality, is the key aspect
I'm actually quite frugal, having never acquired the costly luxury items of a wife and children, but the lessons here are not about frugality, rather about clarity of purpose.
I have a $\$$2000 17mm ultra-wide angle tilt-shift lens on my wishlist, as a want. I do want to buy it, though I don't need it for now. Once I'm convinced that the lens on the camera, rather than my skills as a photographer, is the binding constraint in my photography, I plan to buy the lens. (Given the low speed at which my photography skill is improving, this may be a non-issue. ☺)
Many of our decisions are driven by underlying identity or symbolic reasons; other decisions are driven by narrowly framed problems; some decisions are just herd behavior or influenced by information cascades that overwhelm reasonable criteria; others still are purely hedonic, in-the-moment, impulses. Clarity of purpose avoids all these. I ask:
Why am I doing this, really?
I was surprised at how many times the answer was "erm...I don't know," "isn't everybody?" or infinitely worse "to impress X." These were not reasonable criteria for a decision. (Note that this is not just about purchase decisions, it's about all sorts of little decisions one makes every day, which deplete our wallets but also our energy, time, and patience.)
Clarity of purpose is hard to achieve during normal working hours, shopping, or the multiple activities that constitute a lifestyle. Borrowing some tools designed for lifestyle marketing, I have a simple way to do a "personal lifestyle review" using the real person "me" as the persona used in lifestyle marketing analysis. Adapted from the theory, it is:
1. Create a comprehensive list of stuff (not just material possessions, but relationships, work that is pending, even persons in one's life).
2. Associate the each entry in the stuff to a sub-persona (for non-marketers this means to a part of the lifestyle that is more or less independent of the others).
3. For each sub-persona, determine the activities which have given origin to the stuff.
4. Evaluate the activities using the "clarity of purpose" criterion: why am I doing this?
5. Purge the activities that are purely symbolic and those that were adopted for hedonic reasons but do not provide the hedonic rewards associated with their cost (in money, constraints to life, time, etc), plus any functional activities that are no longer operative.
6. Guide life decisions by the activities that survive the purge. Revise criteria only by undergoing a lifestyle review process, not by spur-of-the-moment impulses.
(This procedure is offered with no guarantees whatsoever; marketers may recognize the underlying structure from lifestyle marketing frameworks with all the consumer decisions reversed.)
Less. It works for me.
A final, cautionary thought: if the ideas I wrote here were widely adopted, most economies would crash. But I don't think there's any serious risk of that.
On September 27, 2011, I decided to run a lifestyle experiment. Nothing radical, just a month of no non-essential purchases, the month of October 2011. These are the lessons from that experiment.
Separate need, want, and like
One of the clearest distinctions a "no non-essential purchases" experiment required me to make was the split between essential and non-essential.
Things like food, rent, utilities, gym membership, Audible, and Netflix I categorized as essential, or needs. The first three for obvious reasons, the last three because the hassle of suspending them wasn't worth the savings.
A second category of purchases under consideration was wants, things that I felt that I needed but could postpone the purchase until the end of the month. This included things like Steve Jobs's biography, for example. I just collected these in the Amazon wish list.
A third category was likes. Likes were things that I wanted to have but knew that I could easily live without them. (Jobs's biography doesn't fall into this category, as anyone who wants to discuss the new economy seriously has to read it. It's a requirement of my work, as far as I am concerned.) I placed these in the Amazon wish list as well.
Over time, some things that I perceived as needs were revealed as simply wants or even likes. And many wants ended up as likes. This means that just by delaying the decision to purchase for some time I made better decisions.
This doesn't mean that I won't buy something because I like it (I do have a large collection of music, art, photography, history, science, and science fiction books, all of which are not strictly necessary). What it means is that the decision to buy something is moderated by the preliminary categorization into these three levels of priority.
A corollary of this distinction is that it allows me to focus on what is really important in the activities that I engage in. I summarized some results in the following table (click for bigger):
One of the regularities of this table is that the entries in the middle column (things that are wrongly emphasized) tend to be things that are bought, while entries in the last column (what really matters) tend to be things that are learned or experienced.
Correct accounting focusses on time, not on nominal money
Ok, so I can figure out a way to spend less in things that are not that necessary. Why is this a source of happiness?
Because money to spend costs time and I don't even get all the money.
When I spend one hour working a challenging technical marketing problem for my own enjoyment, I get the full benefit of that one hour of work, in the happiness solving a puzzle always brings me. When I work for one hour on something that I'd rather not be doing for a payment of X dollars, I get to keep about half of those X dollars (when everything is accounted for). I wrote an illustration of this some time ago.
In essence, money to spend comes, at least partially from doing things you'd rather not do, or doing them at times when you'd rather be doing something else, or doing them at locations that you'd rather not travel to. I like the teaching and research parts of my job, but there are many other parts that I do because it's the job. I'm lucky in that I like my job; but even so I don't like all the activities it involves.
The less money I need, the fewer additional things I have to do for money. And, interestingly, the higher my price for doing those things. (If my marginal utility of money is lower, you need to pay more for me to incur the disutility of teaching that 6-9AM on-location exec-ed seminar than you'd have to pay to a alternate version of me that really wants money to buy the latest glued "designer" suit.)
Clarity of purpose, not simply frugality, is the key aspect
I'm actually quite frugal, having never acquired the costly luxury items of a wife and children, but the lessons here are not about frugality, rather about clarity of purpose.
I have a $\$$2000 17mm ultra-wide angle tilt-shift lens on my wishlist, as a want. I do want to buy it, though I don't need it for now. Once I'm convinced that the lens on the camera, rather than my skills as a photographer, is the binding constraint in my photography, I plan to buy the lens. (Given the low speed at which my photography skill is improving, this may be a non-issue. ☺)
Many of our decisions are driven by underlying identity or symbolic reasons; other decisions are driven by narrowly framed problems; some decisions are just herd behavior or influenced by information cascades that overwhelm reasonable criteria; others still are purely hedonic, in-the-moment, impulses. Clarity of purpose avoids all these. I ask:
Why am I doing this, really?
I was surprised at how many times the answer was "erm...I don't know," "isn't everybody?" or infinitely worse "to impress X." These were not reasonable criteria for a decision. (Note that this is not just about purchase decisions, it's about all sorts of little decisions one makes every day, which deplete our wallets but also our energy, time, and patience.)
Clarity of purpose is hard to achieve during normal working hours, shopping, or the multiple activities that constitute a lifestyle. Borrowing some tools designed for lifestyle marketing, I have a simple way to do a "personal lifestyle review" using the real person "me" as the persona used in lifestyle marketing analysis. Adapted from the theory, it is:
1. Create a comprehensive list of stuff (not just material possessions, but relationships, work that is pending, even persons in one's life).
2. Associate the each entry in the stuff to a sub-persona (for non-marketers this means to a part of the lifestyle that is more or less independent of the others).
3. For each sub-persona, determine the activities which have given origin to the stuff.
4. Evaluate the activities using the "clarity of purpose" criterion: why am I doing this?
5. Purge the activities that are purely symbolic and those that were adopted for hedonic reasons but do not provide the hedonic rewards associated with their cost (in money, constraints to life, time, etc), plus any functional activities that are no longer operative.
6. Guide life decisions by the activities that survive the purge. Revise criteria only by undergoing a lifestyle review process, not by spur-of-the-moment impulses.
(This procedure is offered with no guarantees whatsoever; marketers may recognize the underlying structure from lifestyle marketing frameworks with all the consumer decisions reversed.)
Less. It works for me.
A final, cautionary thought: if the ideas I wrote here were widely adopted, most economies would crash. But I don't think there's any serious risk of that.
Subscribe to:
Posts (Atom)