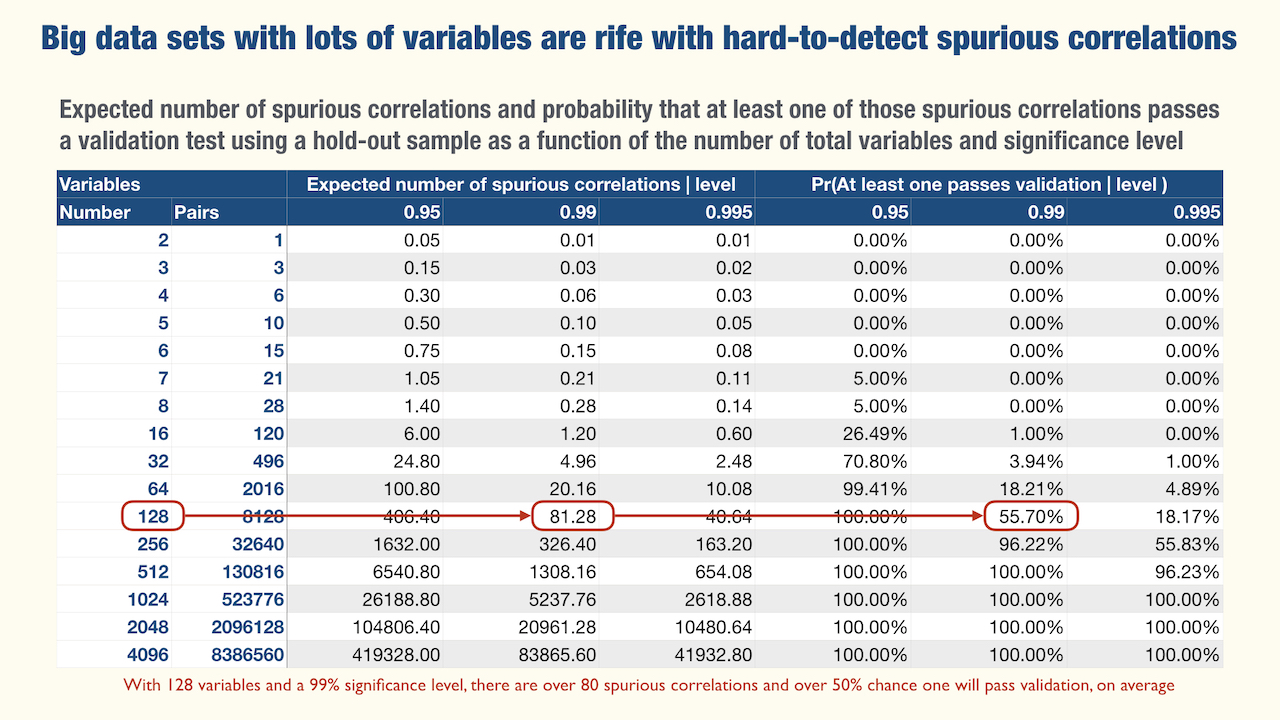
Statistics are weird. But it all makes sense.
Let's say we have 3 variables and 600 measurements, in other words 600 data points with three dimensions or a 600-row matrix with three columns; or this chart:
These are simulated data, drawn from three Normal distributions with variance 1 and means $\mu_A = 0, \mu_B = 0.25,$ and $\mu_C = 0.5$. The distributions are:
There's considerable overlap between these distributions, so any single point is insufficient to determine any relationships between $A$, $B$, and $C$.
Let's say we want to have "99.9 percent confidence" in our assertions. What does that "99.9 percent confidence" mean? The statistical meaning is that there's at most 0.1 percent chance that if the data were generated by "the null hypothesis" (which in our case is that any two distributions are the same) we'd see a test statistic above the critical value.
Test statistic?! Critical value?!
Yes. A test statistic is something we'll compute from the data (a 'statistic') in order to test it. In our case it'll be the difference of the empirical, or sample, means divided by the standard error of those empirical means.
If that number, a summary of the difference between the samples, scaled to deal with the randomness, is greater than some value --- the critical value --- we trust that it's too big to be the result of the random variation. At least we trust it to be too big 99.9 percent of the time.
Okay, that statistics refresher aside, what can we tell from a sample of 25 points? Here are the distributions of those means:
Note how the distributions of the means are much narrower than the distributions of the data. (The means don't change.) That's the effect of averaging over 25 data points. The variance of the mean is $1/25$ and the standard deviation of the mean, called the standard error to avoid confusion with the standard deviation of the data, is $1/\sqrt{25}$.
Someone with a vague memory of a long-forgotten statistics class may recall seeing a $\sigma/\sqrt{n-1}$ in this context and try to argue that 25 should be a 24. And they'd be right if we were estimating the standard error of the population data from the standard error of the sample data; but we're not. Our data is simulated, therefore we know the standard error and we're using that to simplify things like this. Another one of which is the next one: the critical value.
Knowing the distributions lets us bypass one of the most overused jokes in statistics, the Student T ("how do you make it? Boil water, steep the student in it for 3 minutes"; student tea, get it?). More seriously, when the standard error is estimated from the sample data, the critical value is derived from a Student's T distribution; in our case we'll pick one derived from the Normal distribution, which has the advantage of not depending on the size of the sample (or, as it's called in statistics, the number of degrees of freedom in the estimation).
Now for the critical value. We're going to choose a single-sided test, so when we say $A \neq B$, we're really testing for $A < B$.
So how do we test whether some estimate of $(\mu_B - \mu_A)/(\sigma/\sqrt{n})$ is statistically greater than zero? We test the difference in empirical means, $M_A - M_B$, instead of $\mu_B - \mu_A$; since $M_A$ and $M_B$ are averages of Normal variables their difference is a Normal variable; and dividing the difference by the standard error makes it a random variable that is normally distributed with mean zero and variance one, a standard Normal variable, usually denoted by $Z$, hence this sometimes is called a z-test.
Observation: we're dividing the difference of the means by $\sigma/\sqrt{n}$; with $\sigma=1$, we're multiplying that difference by $\sqrt{n}$.
All we need to do now is determine whether $(M_B - M_A)\, \sqrt{25}$ is above or below the point $z^{*}$ in a standard Normal distribution where $F_{Z}(z^{*}) = .999$. That point is the critical value.
(If that scaled difference falls into the blue shaded area, then we can't reject the possibility that it was generated by randomness, instead of actual difference, with the probability that we selected; in the diagram it's 0.99, for our purposes in this post will be 0.999.)
Thanks to the miracle of computers we no longer need to look up critical values in books of statistical tables, like the peasants of old. Using, for example, the inverse normal distribution function of Apple Numbers, we learn that $F_Z(z^*) = 0.999$ implies $z^{*} = 3.09$.
So, with a sample of 25 data points, what can we conclude?
Between $A$ and $B$ our test statistic is $0.25 \times 5 = 1.25$, well below 3.09. So, $A = B$.
Between $B$ and $C$ our test statistic is $0.25 \times 5 = 1.25$, well below 3.09. So, $B = C$.
Between $A$ and $C$ our test statistic is $0.5 \times 5 = 2.5$, still below 3.09. So, $A = C$.
That was a lot of work to prove what we could see from the picture with the distributions for the average of 25 points: too much overlap and no way to tell the three variables apart from a sample of 25 points.
Ah, but we're leveling up! 100 points. Here are the distributions for the averages of 100-point samples:
Between $A$ and $B$ our test statistic is $0.25 \times 10 = 2.5$, well below 3.09. So, $A = B$.
Between $B$ and $C$ our test statistic is $0.25 \times 10 = 2.5$, well below 3.09. So, $B = C$.
Between $A$ and $C$ our test statistic is $0.5 \times 10 = 5$, well above 3.09. So, $A \neq C$.
Now this is the weird case that gets people confused: $A = B$, $B = C$, but $A \neq C$! Equality is no longer transitive. And it does depend on $N$.
But wait, there's more. 300 more data points, and we get the 400 point case, with the following distributions:
Between $A$ and $B$ our test statistic is $0.25 \times 20 = 5$, well above 3.09. So, $A \neq B$.
Between $B$ and $C$ our test statistic is $0.25 \times 20 = 5$, well above 3.09. So, $B \neq C$.
Between $A$ and $C$ our test statistic is $0.5 \times 20 = 10$, well above 3.09. So, $A \neq C$.
Equality is again transitive. So there's only a small range of $N$ for which statistics are weird. (Not hard to figure out that range: consider it an entertaining puzzle.) This gets more complicated if those variables have different variances.
One has to be carefull with drawing inferences about equality (real equality) from statistical non-significant differences. Especially when there are small data sets and test values close to the critical values.